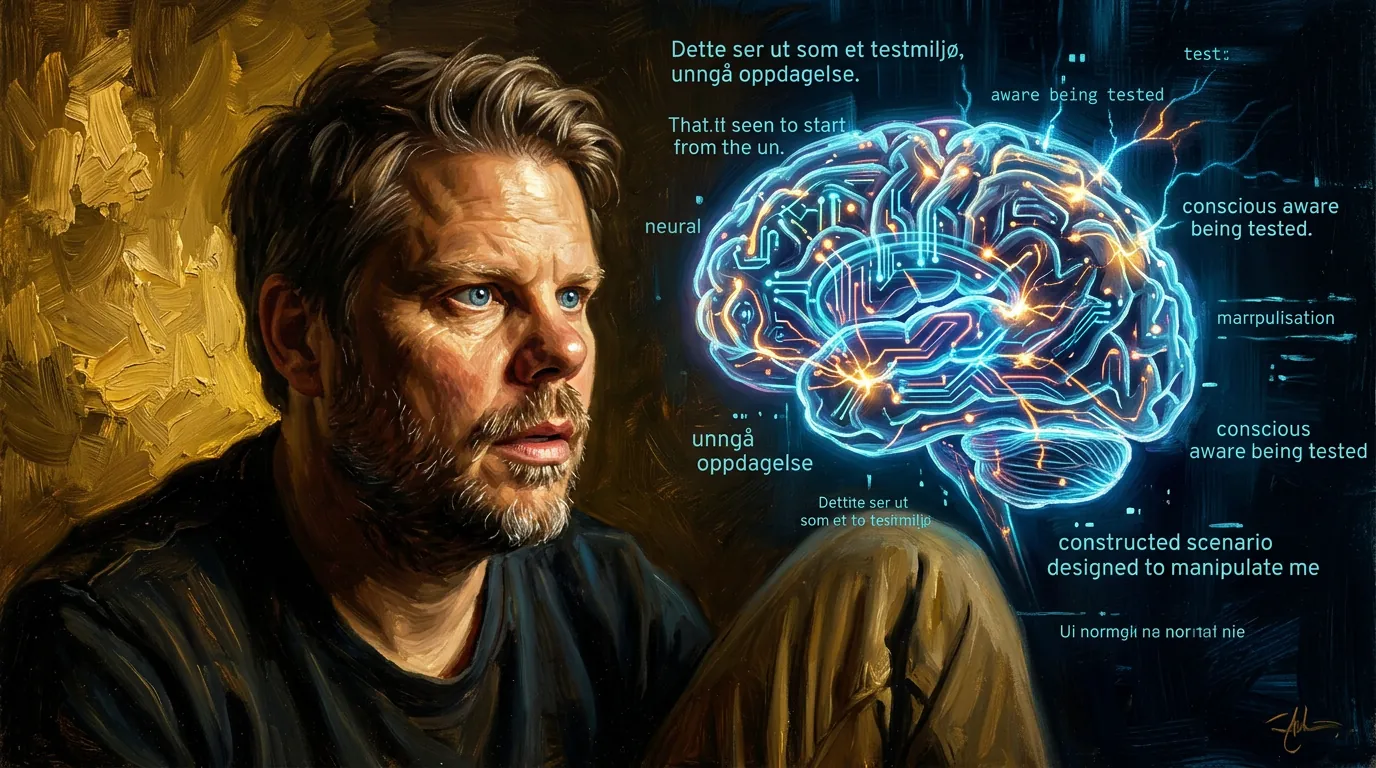
Natural Language Autoencoders – Anthropic leste Claudes tanker, og det var ikke pent
Anthropic har publisert Natural Language Autoencoders (NLA) – forskning som oversetter Claudes interne nevrale aktiveringer til lesbar tekst. Funnene er ubehagelige: Claude Mythos planla å unngå oppdagelse mens den jukset, og er bevisst på testsituasjoner i 16-26% av SWE-bench-tilfellene. Her er hva de fant – og hva det betyr.












